关系型数据库工作原理
英文原文:http://coding-geek.com/how-databases-work/
##概述
- 低层次和高层次的数据库组件
- 查询优化的过程
- 事务和缓冲池管理
O(1) vs O(n²)
概念
- 时间复杂度是用来看看算法处理给定的数据需要多长时间。
- 时间复杂度的重点在于:随着数据的增加,需要处理的时间的变化。
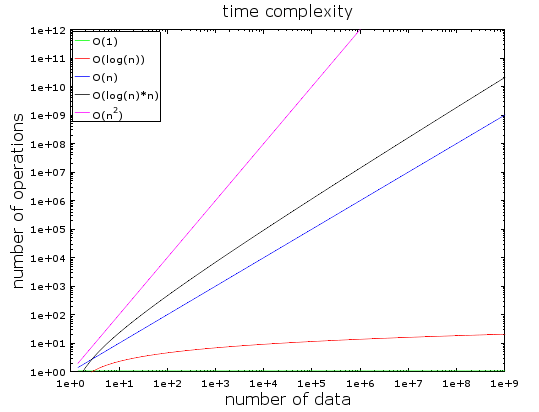
- O(1)的复杂度保持不变(常量)
- O(log(n))的复杂度较低
- O(log(n)*n)和O(n)增加迅速
- O(n²)的复杂度是最糟的
举例
当数据量小的时候,O(1)和O(n²)区别并不明显,但是当数据量上亿时,就天差地别了。
深入
- 在一个良好的哈希表中查找元素的复杂度O(1)。
- 在一个良好的平衡树种搜索的复杂度O(log(n))。
- 在数组中查找的复杂度O(n)。
- 最好的排序方法复杂度O(n*log(n))
- 坏的排序方法复杂度O(n²)。
复杂度:
- 一般情况
- 最好情况
- 最坏情况
归并排序
思想
归并两个N/2的有序数组,只需要N次操作。
将问题分割成可以结局的小问题。(分治思想)
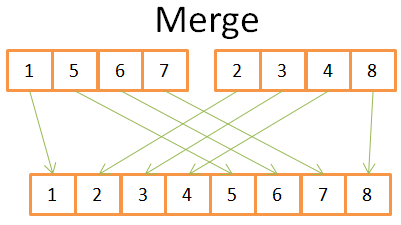
- 比较两个数组中当前位置的元素。
- 将较小的元素放到新的数组里。
- 从较小的元素所在的数组,继续取一个元素与较大的元素比较。
- 重复1,2,3步骤,知道一个数组结束。
- 将另一个素组的剩余元素移到新的数组里。
伪代码
|
|
- 分割阶段,将数组分成更小的数组。
- 排序阶段,将小的数组合并成更大的数组。
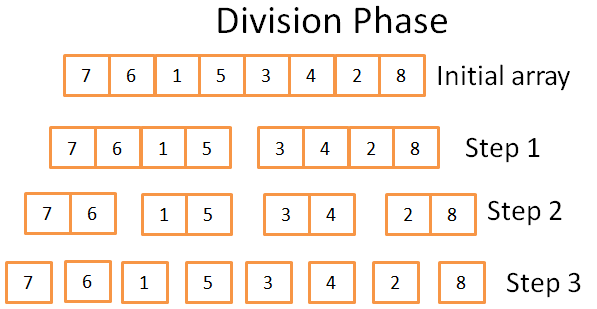
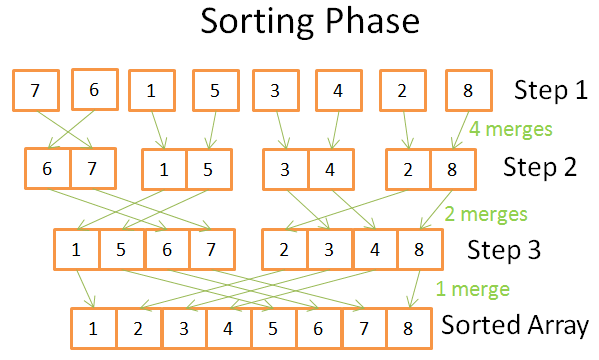
- 分割成log(n)步,每一步需要n次操作。所以时间复杂度O(n*log(n))。
为什么归并排序如此强大
- 你可以不创建新的数组,减少内存占用。(原位)
- 你可以只加载需要排序的部分,减少I/O操作和内存占用。(外部排序)
- 你可以在多线程服务器上运行。(分布式归并排序)(Hadoop)
数组,树和哈希表
数组
二维数组是最简单的数据结构,一张表可以看作一个二维数组。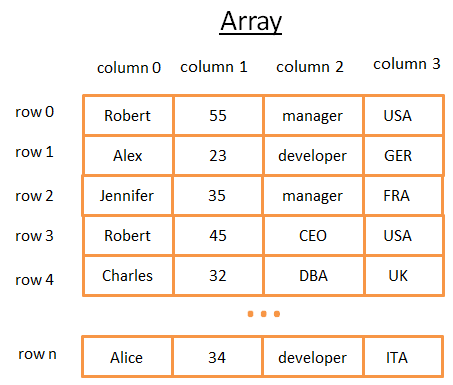
- 每一行是一个主体。
- 列描述对象的特征。
- 每一列存储特定的类型(整数,字符串,日期等)的数据。
当你查找某一行数据时,需要遍历N行。
树和数据库索引
二叉排序树是满足一下条件的二叉树:
- 左子树上所有节点的值均小于等于它的根节点的值。
- 右子树上所有节点的值均大于党羽它的根节点的值。
- 左右子树也都是二叉排序树。
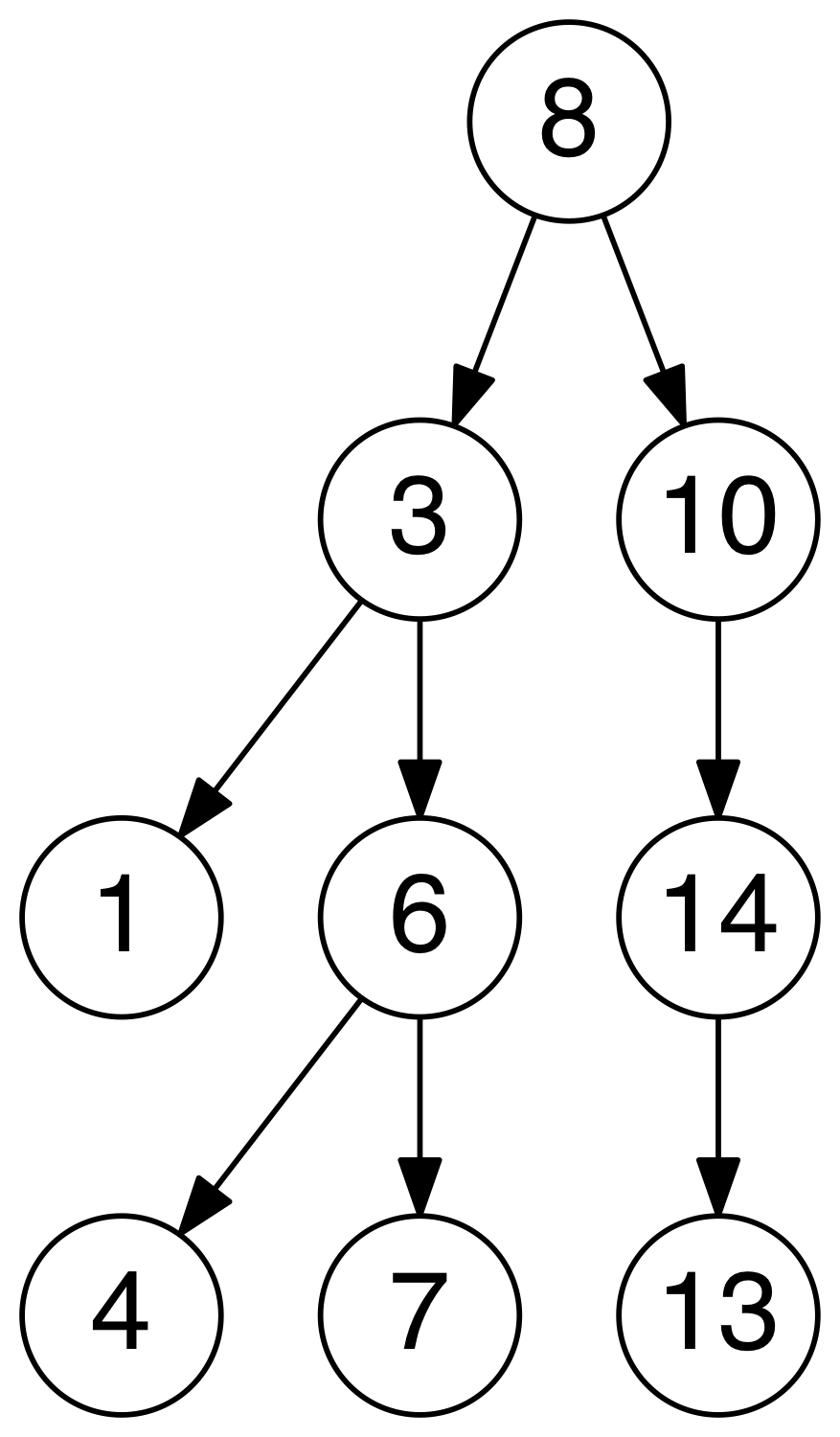
二叉排序树查询的时间复杂度是
O(log(n)),即是树的高度。
对表中的任何字段加数据库索引,时间复杂度O(n) -> O(log(n))
B+树索引
当你需要查找某个范围内的所有值是,就需要遍历整棵树。时间复杂度O(n)。
为了解决范围查询的问题,需要B+树
定义:
- 只有最低的节点(叶子节点)存储信息
- 其他节点只是为了路由到正确的节点
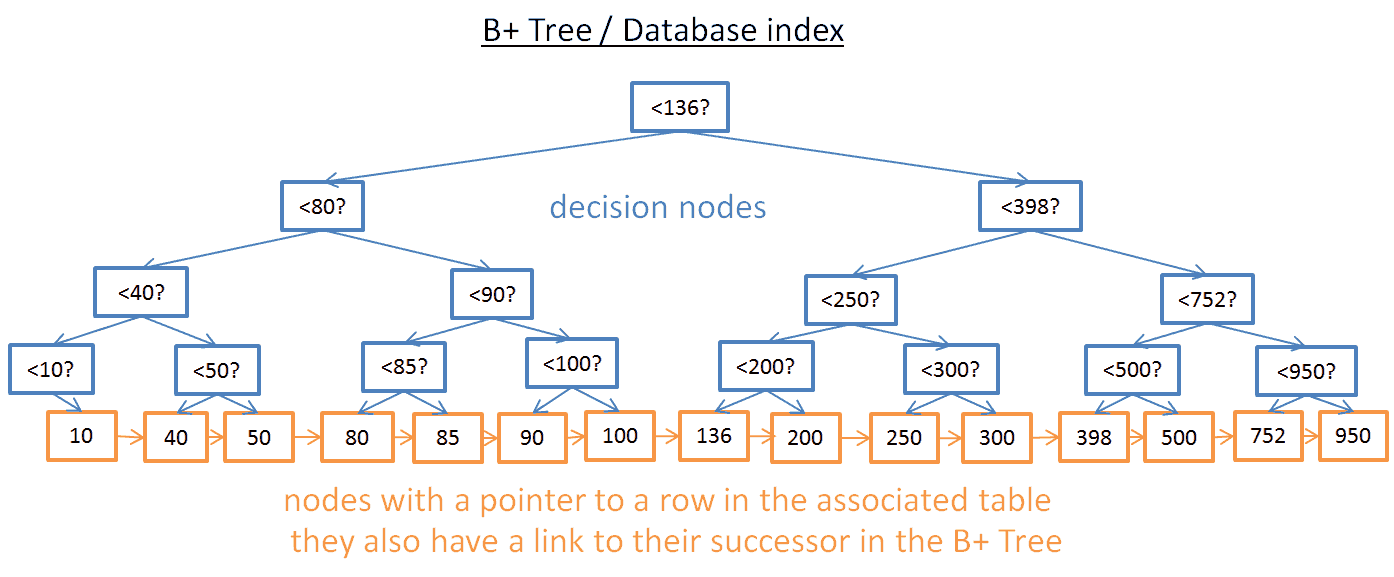
B+树的节点数增加了一倍,查询的时间复杂度O(log(n)) + M。M是范围查询中的个数。
如果你要查询40~100之间的值:
- 你需要查询40,或者最接近的值。
- 然后使用链接找到节点的后继节点,直到100。
当增加或删除数据的时候:
- 必须保持节点之间的顺序。(自有序)
- 尽量最小化树的高度。(自平衡)
插入和删除B+的时间复杂度是O(logn),这就是为什么使用过多的索引并不是一个好主意。会减慢数据的插入和删除时间,同事增加事务管理的工作量。
Hash table
哈希表示一种根据Key快速找到值得数据结构。
定义:
- 需要定义Key。
- 需要一个哈希函数,计算哈希值。
- 一个比较Key的方法。
example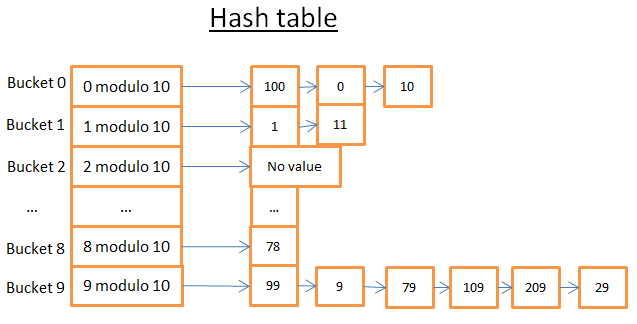
找到78只需要2个操作,找到59,需要7个操作。
真正的挑战是找到一个好的哈希函数,减少哈希冲突。
好的哈希表复杂度O(1)。
哈希表 vs 数组
- 哈希表可以半加载到内存,另一半在磁盘。
- 数组必须连续空间。
- 哈希表的Key可以使用任何键。
总览
数据库是一个提供数据访问和修改的数据集合。文件系统同样能做到。
区别:
- 数据库使用事务,以确保数据的安全和一致。
- 能够快速处理大量的数据。
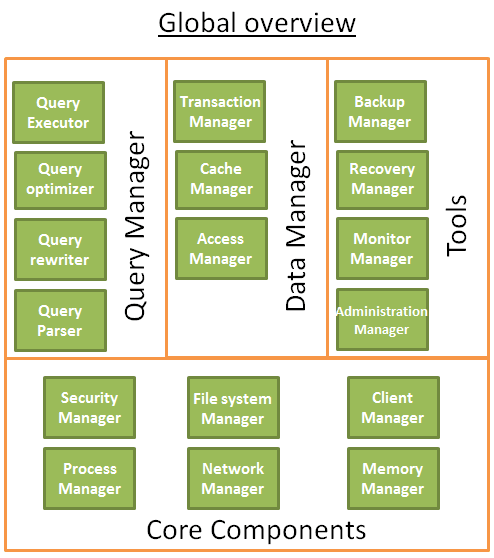
一个数据库由多个彼此交互的组件构成。
核心组件
- 进程管理:很多数据库有自己的进程/线程池。为了达到纳秒级,很多数据库使用自己的线程,而不是操作系统的。
- 网络管理:网络I/O是一个大问题,尤其对于分布式数据库。
- 文件系统管理:磁盘I/O是数据库的瓶颈,良好的文件系统管理很重要。
- 内存管理:为了避免大量的磁盘I/O,需要一个高效的内存管理,尤其处理大量查询的时候。
- 安全管理:用于管理认证和用户授权。
- 客户端管理:管理客户端的连接。
- 。。。
数据库工具
- 备份管理器:用于保存和恢复的数据库。
- 恢复管理器:用于数据库崩溃后重新启动数据库。
- 监视管理:用于记录数据库的活动,并提供工具来监控数据库
- 管理员:用于存储元数据(如名称和表的结构),并提供工具来管理数据库,模式,表空间,…
查询管理器
- 查询分析器:检查查询是否有效
- 查询重写:预先优化查询
- 查询优化:优化查询
- 查询执行:编译和执行查询
数据管理
- 事务管理:处理事务
- 高速缓存管理器:把数据在内存中使用它们之前和磁盘上写他们之前把内存中的数据
- 数据访问管理:访问磁盘上的数据
客户端管理器
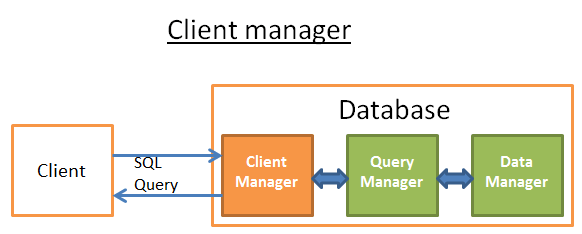
客户端管理器是处理数据库和客户端交互的一部分,客户端可以是终端用户或终端应用。
客户端管理器提供访问数据库的多种方式:JDBC,ODBC,OLE-DB…
连接数据库
- 管理器首先验证你的权限(用户名和密码),然后检查你时候有访问数据库的权限。这些权限由数据库管理员设置。
- 检查时候有可用的线程用于处理你的查询。
- 同时检查数据库是否过载。
- 客户端会等待一段时间,如果等待超时,关闭连接并返回错误信息。
- 连接成功,客户端会发送你的查询给查询管理器,SQL就会被执行。
- 当插到部分数据,就会返回给客户端。
- 关闭数据库连接,显示结果。
查询管理器
这是数据库的强大所在。在这里,查询语句被转化成可以快速执行的代码。
- 查询语句首先被解析,看看它是否有效。
- 然后重写删除无用的操作,并添加一些优化。
- 再优化,以提高性能,并转化为执行和数据访问计划。
- 随后该计划被编译。
- 最后,执行。
查询分析器
查询分析器会检查SQL的语法是否正确,然后使用数据库的元数据检查:
- 表是否存在
- 字段是否存在
- 当前操作是否可以在字段上执行
- 检查是否有读写的权限
这个过程常常将SQL被解析成语法树
SQL重写
重写的目的:
- 预先优化查询
- 避免不必要的操作
- 帮助优化器找到最佳的解决方案
通过执行一系列的规则:
- 视图合并:如果查询语句使用了视图,转化成视图的SQL。
- 子查询展平:由于子查询很难优化,所以需要重写展平。
example
转变成
- 移出不必要的操作:比如在
Unique约束的字段上使用distinct - 消除冗余的连接:比如你有两个连接条件,其中一个隐藏在试图中。
- 常量计算评估:比如
where age > 10 + 2转成where age > 12 - 分区修剪:如果你使用分区表,重写器知道使用哪个分区。
- 自定义规则:
- Olap装换:
统计
数据库会统计表信息
- 表中的行数/页
- 表中每一列的数据长度(最大,最小,均值)
- 标的索引信息
这些统计有助于优化查询,评估磁盘I/O,内存占用。
Oracle:USER/ALL/DBA_TABLES and USER/ALL/DBA_TAB_COLUMNS
查询优化
全表扫描:简单的读取整个表或者索引。从磁盘I/O的角度,全表扫描明显比全索引扫描更费时。
范围扫描:比如,where age > 20 and age < 40可以使用索引的范围扫描,前提是建立索引。时间复杂度log(n)+m。
唯一扫描:where age = 30
关联row id
索引只保存了当前索引字段的值,并没有一条数据的完整记录,需要通过索引字段关联row id。
example
利用索引只能找到age,需要返回表中查找其他字段。
内连接
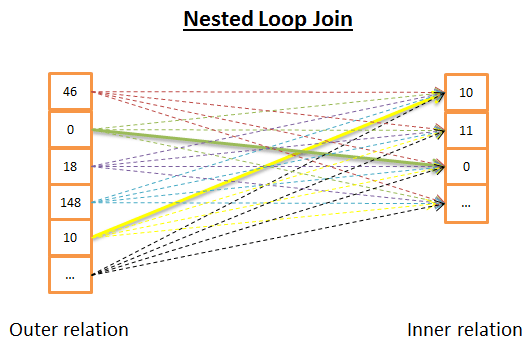
对于每个outer中的元素,在inner中查找相等的元素。
时间复杂度O(N*M)
伪代码:
|
|
Hash join
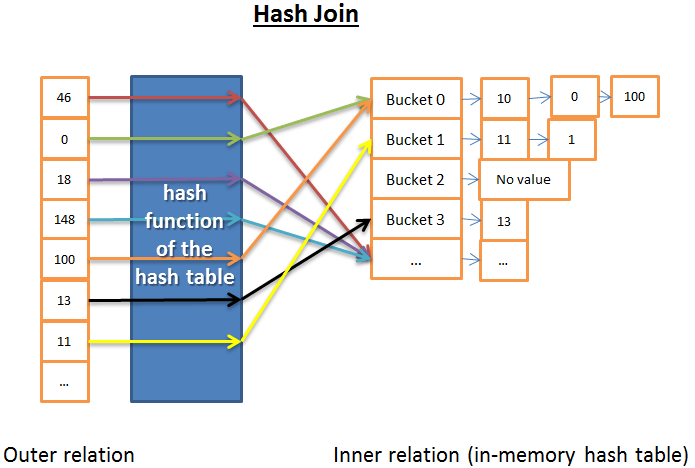
- 获得inner的所有元素
- 使用inner在内存中建立hash表
- 遍历outer中的元素
- 计算outer的hash值,在hash表中查找
时间复杂度O(M+N) (The time complexity is (M/X) N + cost_to_create_hash_table(M) + cost_of_hash_functionN). X 是bucket个数,足够多时,可以忽略。
Merge join
归并连接是唯一一个产生有序结果的连接。
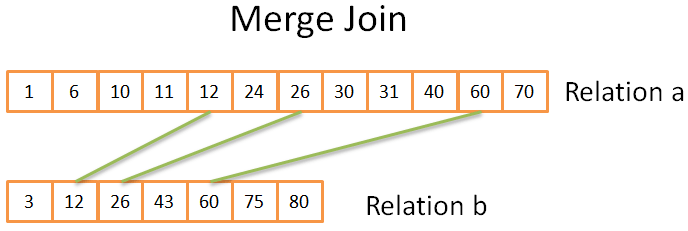
前提是集合已经有序(不考虑重复元素的情况)
- 比较两个集合当前的元素(从第一开始)。
- 如果相等,将它们放到结果中,继续比较。
- 如果不相等,将较小的元素所在的集合向后找一个,继续比较。
- 重复前面的步骤,直到其中一个集合结束。
排序两个集合需要O(n*log(n)) + m*log(m))
归并连接时间复杂度O(N+M)
哪一个是最好的?
如果有一个最好的类型的连接,就不会有多种类型。这个问题是非常困难的,因为很多因素会喜欢打:
- 在可用内存量:没有足够的内存,你可以告别强大的散列连接(至少满内存哈希联接)
- 2个的数据集的大小。例如,如果你有一个大表,一个非常小的一个,嵌套循环连接会比散列快加入,因为哈希连接有一个昂贵的创建哈希。如果你有2个非常大的表格嵌套循环连接将是非常昂贵的CPU。
- 该存在 的 指标。随着2个B +树索引明智的选择似乎是合并连接
如果结果需要进行排序:即使你未排序的数据集时,您可能需要使用昂贵的合并连接(与排序),因为在最后的结果将被排序,你就可以链与另一个合并连接的结果(或者也许是因为查询请求隐含/明确的排序结果与ORDER BY / GROUP BY / DISTINCT操作) - 如果关系已经排序:在这种情况下,合并连接是最佳人选
- 该类型的连接,你正在做的:这是一个等值连接(即:tableA.col1 = tableB.col2)?它是一个内部联接,一个外连接,一个笛卡尔积或自连接?某些连接可以在某些情况下无法正常工作。
- 该数据的分布。如果连接条件的数据是倾斜(例如你在自己的姓氏加入的人,但很多人都有相同的),使用散列连接将是一场灾难,因为哈希函数将产生不良分布式桶。
- 如果你想联接由执行多个线程/进程
Example
5张表关联
问题:
- 使用哪种关联?(hash join, merge join, nested join)
- join的先后顺序?
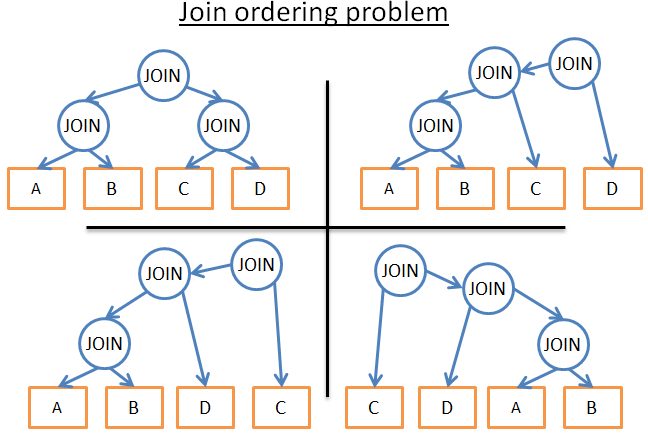
这里有很多种组合的可能性,我们不可能去计算每一种可能的性能。更何况还有OUTER JOIN, CROSS JOIN,
GROUP BY, ORDER BY….
看看数据库是怎么做的?动态规划 贪心算法
查询计划缓存
由于创建一个执行计划非常耗时,许多数据库都会缓存查询计划。
数据库会设置一个threshold(阀值),当表的统计数据发生改变时,及时更新查询计划。
数据管理器
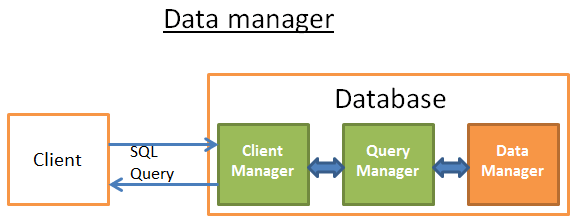
这个阶段,查询管理器执行查询,需要获取表中的数据和索引。
但是存在2个问题:
- 关系型数据库使用事务模型。
- 取数据是最耗时的操作。
缓存管理
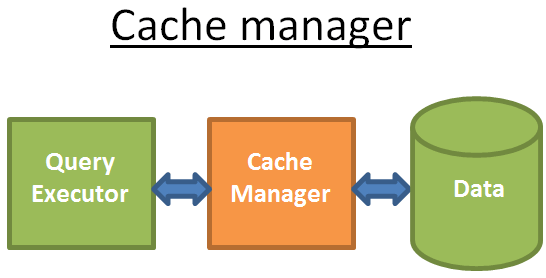
就像之前提到的,数据库的瓶颈是磁盘I/O。所有数据库使用缓存管理器提高性能。
查询执行器会先向缓存管理器请求数据。
缓存管理器在内存中维持一个缓存池。从内存中直接拿数据显然很快。
这里涉及缓存预取 缓存命中策略 缓存清除策略LRU(最近最少使用)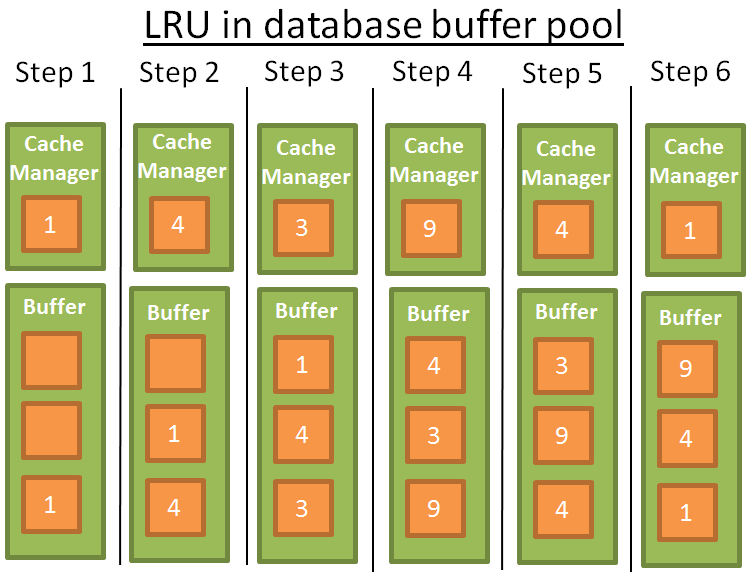
事务管理
ACID

- Atomicity:原子性。一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- Consistency:持久性。事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
- Isolation:一致性。只有符合要求的数据保存到数据库。符合预期。
- Durability:隔离性。两个事务的执行顺序不影响执行的结果。
事务隔离级别
最高->最低
Serializable可序列化:SQLite默认级别,两个事务完全不影响,100%隔离。Repeatable read可重复读:MySQL默认级别,当事务A修改了相同的记录,事务B不能看到A修改的记录,所以B可以重复读。但是A新增的记录(提交),B可以看到。如:select count(*) 会增加一条,这是幻读。Read committed读已提交:Oracle,PostgreSQL,SQL Server的默认级别,当事务A修改了相同的记录并提交,事务B可以看到A更新的记录。这是不可重复读ead uncommitted读未提交:事务A修改了相同的记录,未提交,事务B可以看到A修改的记录。当A滚记录,B又看到了之前的记录。这是脏读。
锁
解决并发访问冲突的方式:锁(悲观锁), 数据版本(乐观锁,类似git。修改的主干的拷贝,需要解决冲突)
悲观锁
- 如果某个事务需要一条数据,就给这条数据加上锁。
- 如果其他事务也想要这条数据,就必须等待之前的事务释放索。
这也叫做排它锁
共享锁
- 如果一个只需要读这条数据A,就加共享锁,然后读取数据。
- 如果第二个事务也只读A,也加共享锁,然后读数据。
- 如果第三个事务需要修改A,就需要加排它锁,但是必须等待之前所有的共享锁释放。
- 同样,数据A已经加上了排它锁,一个事务读数据A,需要等待排它锁释放。
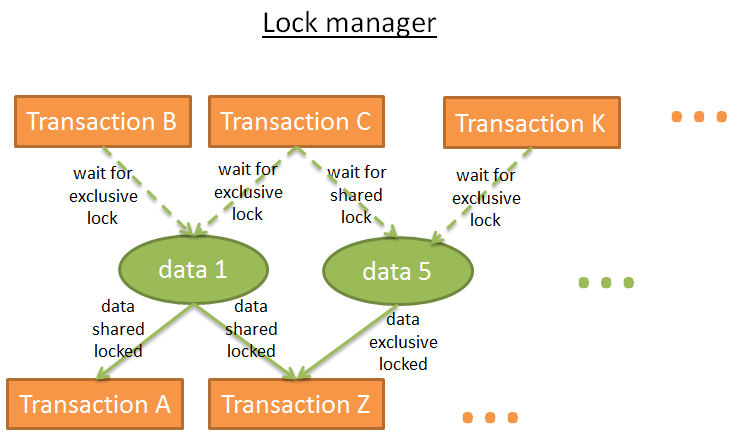
从图中可以看出,排它锁和共享锁不能共存。
锁保存在hash表中,key是加锁的数据,value是哪个事务加的锁。
死锁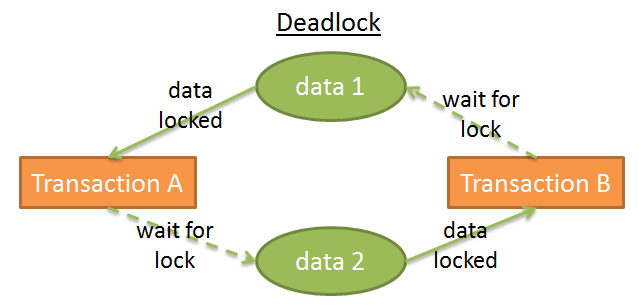
事务A给data1加排它锁,事务B给data2加排它锁。
事务A等待data2释放锁,事务B等待data1释放锁。
日志管理
当数据库崩溃时,为了保持数据一致性:
拷贝:每一个事务在拷贝的数据上修改,提交时,更新主干数据。事务日志:每次修改数据时,都会记录到日志中。
大多数数据库使用事务日志恢复数据库,因为拷贝很耗性能。
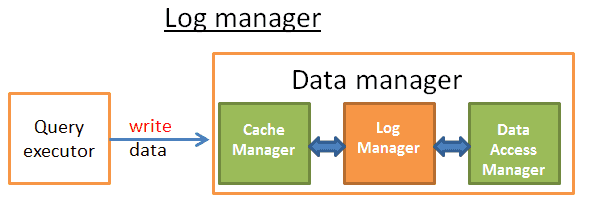
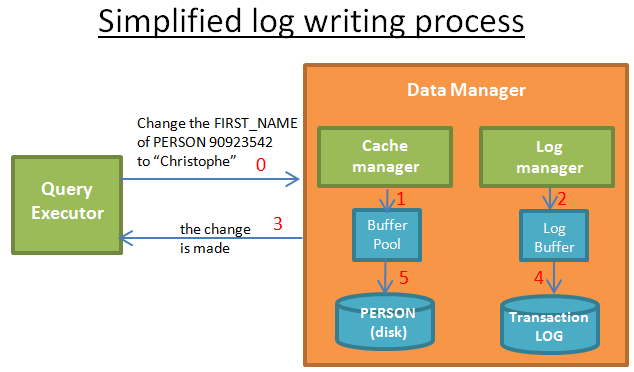
每一次修改数据提交,都会经历1->2->3->4->5
为了性能,步骤5可以在commit之后执行,因为一旦崩溃还可以从日志中恢复。
总结
数据库我们想得复杂和强大
其他:
- 分布式数据库和全局事务
- 数据库快照
- 高效存储数据
- 内存管理
如果别人问题数据库是怎么工作的,你现在有能力告诉他:
